From Vision to Reality: A Practical Guidance for Building RAG-Powered Conversational Search in E-Commerce
Albert
8/5/202510 min read
This comprehensive guide walks you through building a production-ready RAG-powered conversational search system for e-commerce. We'll cover why conversational search is becoming essential for online retail, demonstrate how RAG solves the cost and performance challenges of LLM-based search, and provide a detailed technical roadmap for implementation. You'll discover practical insights on system architecture and critical operational considerations—from embedding model selection and prompt engineering to monitoring and data maintenance — that theoretical discussions often overlook. Whether you're evaluating the feasibility of conversational search or ready to start building, this guide offers both strategic context and actionable technical guidance.
1. Conversational Search for E-commerce: The Next Frontier
Conversational search for e-commerce is not far off — in the future, users will find items by communicating with a chatbot in natural language, rather than making a relentless effort using the search bar, filters, and facets.
Why? Think about the last time you needed to search for something. Did you use Google, or did you — perhaps unconsciously — turn to ChatGPT, Perplexity, or another LLM first? Just like Apple redefined the smartphone, LLMs will reshape the way people interact with online data.
2. Retrieval-Augmented Generation (RAG): Superpower for LLM-based Search
What's RAG
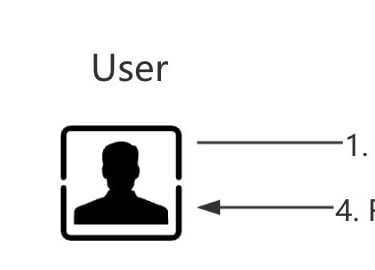
In brief, RAG is a technique that enhances LLMs’ performance by leveraging an external knowledge base. It works by retrieving relevant data from this base, which is then provided as additional context (input) to the LLM, enabling it to generate responses grounded in the specific, retrieved information.
Without RAG, when users query an LLM, the model generates a response based solely on its pre-trained data. The quality and factual accuracy of this response heavily rely on the model’s inherent knowledge and training algorithm.
With RAG, when a user queries the LLM, the query is first passed to a retrieval system to fetch a refined dataset — the most relevant information from the knowledge base — which is then provided as context to the LLM, enabling it to generate a grounded final response.
P1 Direct Prompting VS RAG
How could RAG retrieve most relevant data
At the heart of RAG's retrieval process lies the Vector Database. Consider a product entity, for example, an apple described as: "It's a red, sweet Gala apple from Western Michigan."
In a traditional database, this information might be stored in a structured format, breaking it down into attributes like: Category: Gala / Color: Red / Taste: Sweet / Production area: Western Michigan.
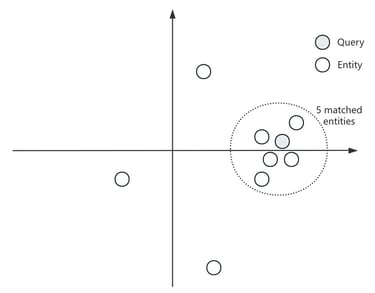
A Vector Database operates fundamentally differently. It uses an embedding model to transform the entire natural language description (e.g., "It's a red, sweet Gala apple from Western Michigan") into a high-dimensional numerical vector. If it's a 1024-dimension vector, this apple might be represented as [0.0013, 0.3309, …, 0.7123]. The distance between two vectors represents their similarity — the closer the vectors are, the more similar the underlying entities.
When a user's query comes in (e.g., "sweet red fruit"), that query is also transformed into a vector of the same dimension using the same embedding model. The "matching" process then becomes a mathematical calculation: finding the closest X product vectors to the query vector based on their numerical distance in this multi-dimensional space.
P2 A simplified matching process
Why RAG is ideal for E-commerce search
Many articles claim that we need RAG to eliminate hallucinations and obtain factual information by sourcing from up-to-date data. From my perspective, however, the adoption of RAG for e-commerce search mainly brings two key benefits: lower cost and faster response time.
Let’s start without RAG. How can we enable conversational search for e-commerce? A common approach is direct prompting, where we send the user’s query along with the entire product catalog to an LLM, such as GPT-4o, via API. With carefully designed prompts, this approach can achieve similar performance to RAG. However, it consumes a significant number of tokens.
Assume there are 10,000 items, each with a 100-word description. Ignoring the user query and response tokens, the input size would still be approximately 1.3 million tokens (10,000 × 100 × 1.3). No current LLMs — ChatGPT, Gemini, Claude — support this kind of input window. And even if they did in the future, the cost would be a major barrier. Based on current pricing — the cost of output tokens is negligible — here’s a simple cost comparison:
For most e-commerce platforms, paying $3–$4 per search query is unacceptable. It also introduces a performance issue: latency. Processing over 1 million tokens can take more than 10 seconds. In a B2C setting, making users wait over 10 seconds just to search is a poor user experience.
With RAG, these concerns go away. You no longer need to process all 10,000 items for each query, which means no input token overload — and no token-induced cost or latency.
Here’s why: the LLM doesn’t handle the entire catalog. Instead, RAG retrieves the top X most relevant items based on vector similarity between the user’s query and the product embeddings. Only the selected X items, along with the query, are sent to the LLM to generate a final response. Assuming each item has a 100-word description and X = 10, the total token input would be roughly 100 × 10 + query tokens ≈ a few thousand tokens.
Result? Much lower cost, faster response time, and a more scalable search experience compared to direct prompting.
3. How to build a RAG-based E-commerce Search
Let's break down this into Process and System Design
Process
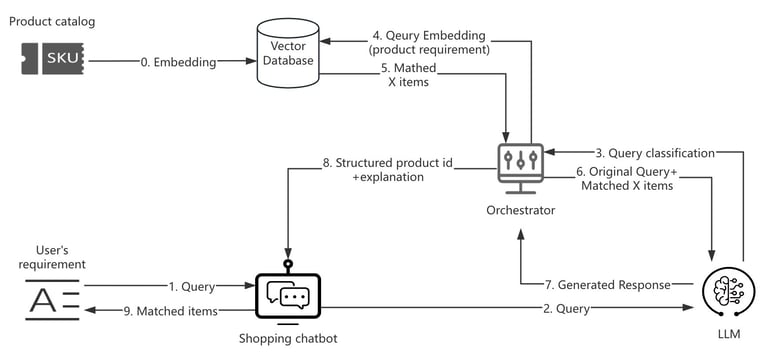
Based on the earlier guidelines, the process of RAG-based e-commerce search unfolds as follows:
All product descriptions are first converted into vectors using the RAG system.
A user expresses their requirement in natural language through a search chatbot.
The LLM behind the chatbot recognizes this as a product query and forwards it to the RAG system.
The RAG system encodes the user’s requirement into a vector using an embedding model.
It then searches the vector database to find the top X closest product vectors.
These X items are returned to the LLM.
The LLM generates a response highlighting these items as the best matches to the user’s query.
Finally, the chatbot displays the results after parsing the LLM’s response.
P3 Data flow
System Design
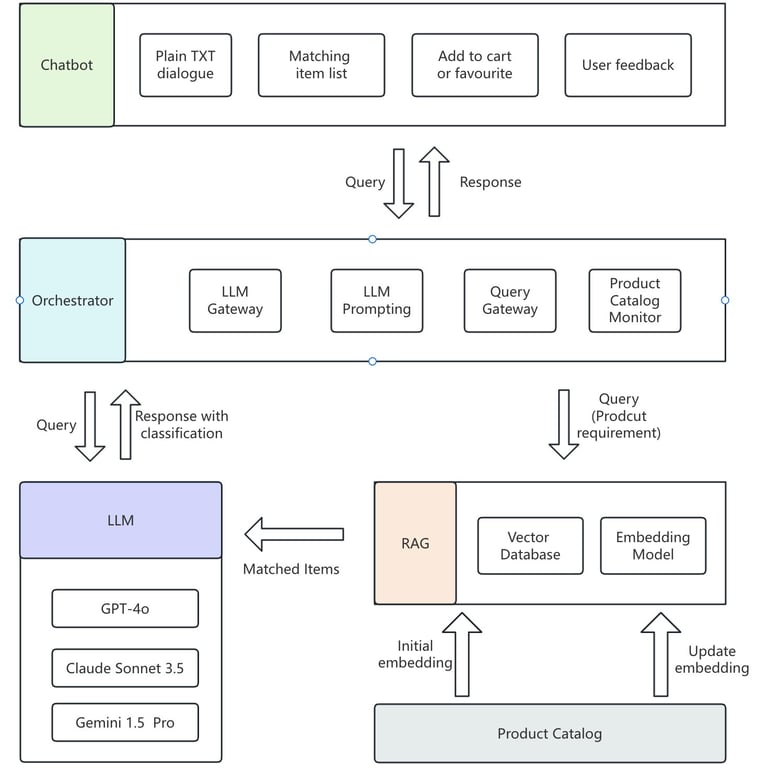
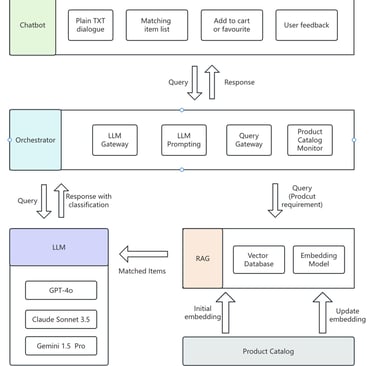
Below is a simplified view of the system architecture.
P4 System architecture of RAG-based Product Search for E-commerce
Implementation Deep Dive:
1) Keep The Prompt Iterated
No one doubts the power of applying LLMs to specific scenarios — but the key to effectiveness lies in prompt engineering.
When it comes to conversational search, the LLM's primary roles are:
Engaging with users to clarify their exact needs.
Returning a refined product list based on recommendations from the RAG system.
Sounds simple enough, right? But let’s go a step further.
You need to define clear boundaries. For example, how should the LLM respond if a user asks something unrelated to product discovery? Or what if they inquire about a competitor’s product? These edge cases must be accounted for.
You also need to guide the LLM on how to draw out user intent. Not every user knows the product terminology — they may only describe a use case. Say someone wants a hiking backpack for a summer weekend trip in the Rocky Mountains. They may not know which features matter — capacity, breathability, hydration compatibility, etc. A well-crafted prompt should establish clear guardrails to help the LLM elicit these needs naturally and accurately.
You won’t land the perfect prompt on your first try. This isn’t a math problem—it’s an iterative process. Craft, test, revise, test again. Prompt design is a cycle of experimentation. You do it over and over — until it just works.
2) Selecting Suitable Embedding Models
To achieve high-precision product search, the embedding model is fundamental. Several strong options are available — such as OpenAI’s text-embedding-3-large, Google’s text-embedding-005, and Cohere’s embed-english-v3.0. It’s difficult to definitively rank them, as performance often varies by use case and dataset. Generally, newer model generations outperform their predecessors.
Key factors to consider:
Input token limit: This restricts how much product description content can be embedded.
Output vector dimension: This determines the structure and precision of your vector database.
Model consistency: The same embedding model must be used for both product catalog and user query. Think of it like encoding protocols — if a teacher only knows student IDs but receives a query in student names, matching becomes impossible.
3) Choosing the Right Vector Dimension
It’s tempting to assume that higher-dimensional vectors lead to better precision — and to a point, that’s true. But there are trade-offs.
Imagine the Solar System, which contains 8 planets. Now, randomly place 100 smaller planets within it. For each added planet, calculate its distance to every original planet, sum those distances, and then select the 10 planets with the smallest total distances as the closest matches.
Now, scale this up to a galaxy with hundreds of billions of planets. The computation becomes extremely complex. More importantly, selecting the 10 closest planets becomes meaningless—because in such a vast space, the calculated distance sums may be nearly identical for many planets, offering little differentiation.
So, what is the guidance for selecting the dimension of the vector database? Usually, this is determined by the embedding model. For example, OpenAI's text-embedding-3-large outputs vectors with an original dimension of 3072 but also supports customized lower dimensions, such as 1024 — a sweet spot for many use cases.
4) Structured Product Catalog is Foundational
A clean, structured catalog enables everything else. Work with your merchandising team to define key product attributes and their values.
A solid schema might include:
Product Name
Brand
Price
Short Description
Specification 1
Specification 2
...
Some platforms skip structure and rely on PDF manuals instead. That’s problematic:
Users struggle to read them.
Embedding models often miss or misinterpret key details in PDFs.
Even switching to long-form natural language descriptions isn't ideal — users won’t read large blocks of text, and many embedding models (e.g., Cohere’s embed-english-light-v3.0) have short context windows (512 tokens or ~400 words). Splitting descriptions into chunks adds complexity and risks semantic loss.
5) Closing the Feedback Loop: Update Product Data Based on Real Queries
Static product descriptions are insufficient for optimal search performance. You might assume users prioritize features 1, 2, and 3, so you emphasize these in your product data. However, users often care about feature 4—which your product actually possesses but isn't documented in your catalog. The result? Lost customers who turn to competitors offering better-described alternatives.
Monitor Search Performance and User Intent
To prevent this, establish a systematic approach to query analysis:
Track and review queries that return poor results or lead to no conversions on a daily or weekly basis.
Identify gaps between user intent and product descriptions.
Expand product attributes based on above analysis.
This analysis often reveals valuable product features that were overlooked during initial catalog creation, allowing you to enhance descriptions with information that directly addresses user needs.
Implement Dynamic Re-embedding
Once you implement necessary updates, maintaining search accuracy requires a robust re-embedding strategy:
Real-time updates: For frequently changing data like price, stock levels, or promotions, trigger immediate re-embedding via event-driven mechanisms
Scheduled updates: For descriptive attributes, implement daily comparison processes that detect changes and queue items for re-embedding. Process these updates in batches during off-peak hours to optimize computational resources while maintaining search relevance.
This dual approach — monitoring user behavior and maintaining data freshness — ensures your conversational search system evolves with both user expectations and product changes, maximizing search effectiveness and customer satisfaction.
6) Consider Hybrid Search — Not Just Semantic Search
Conversational search is, at its core, a form of semantic search. Its strength lies in capturing the full intent behind a user’s query — not just matching keywords. However, not all product discovery tasks require deep semantic understanding. In many cases, a hybrid approach that combines keyword search with semantic search is more effective.
Take this user query: “A black hiking backpack workable on rainy days under $300”. It can be split into:
Category: Hiking Backpack
Color: Black
Price: Under $300
Specification: Workable on rainy days
The first three are perfect for traditional filters. Only the last one benefits from semantic search via RAG.
You can approach this either sequentially or in parallel. In the case above, if you choose a sequential approach, it would look like this:
Step 1 (Keyword): Filter by category, color, and price.
Step 2 (Semantic): Use RAG to evaluate rainproof capability among filtered items.
7) Iterative experimentation for all
There are many variables in the conversational search loop — LLM, prompt design, embedding model, and vector database, to name a few. For each of these, there’s rarely a one-size-fits-all solution that guarantees optimal performance.
Take LLMs, for example. Is OpenAI’s GPT-4o better than Claude Sonnet 3.5 for conversational search? The answer depends on your specific use case, data, and constraints. Finding the ideal combination is less about theory and more about experimentation — learning from results and making adjustments along the way.
That’s why rigorous testing is essential. Precision, recall, and latency must all be measured, benchmarked, and optimized. You might finish coding the core system in two months, but fine-tuning the entire recipe could easily take another two months — or more.
4. Conclusion
Building a RAG-powered conversational search system for e-commerce is both a technical and strategic undertaking. While the core concepts—vector databases, embedding models, and LLM integration—are well-established, success lies in the details: crafting effective prompts, selecting the right models for your use case, maintaining data quality, and continuously optimizing through experimentation.
The transformation from traditional keyword-based search to conversational interfaces isn't just a trend—it's an inevitable evolution in how users discover products online. Early adopters who implement these systems thoughtfully will gain a significant competitive advantage in user experience and conversion rates.
However, building and maintaining a production-ready RAG system requires substantial technical expertise and ongoing optimization. The complexity spans multiple domains: machine learning, system architecture, data engineering, and user experience design. For many e-commerce businesses, the question isn't whether conversational search is valuable, but how to implement it efficiently without diverting core development resources.
This is precisely why we built Evosmarter — a plug-and-play search chatbot that brings enterprise-grade RAG capabilities to e-commerce platforms without the technical complexity. Instead of spending months building and fine-tuning your own system, Evosmarter provides a ready-to-deploy solution that integrates seamlessly with your existing product catalog, allowing you to offer conversational search to your customers within days, not months.
The future of e-commerce search is conversational. The only question is how quickly you'll get there.



Evosmarter
Smarter online shopping starts here
Talk to the founder
albert.jing@evosmarter.com
© 2025. All rights reserved.